


Why creating robots.txt is crucial
Creating a robots.txt file appears to be a key component to effectively managing indexing and ensuring security in the online environment. In this article, we’ll look at the important aspects of creating and using this text file that tells search engines how they should interact with your website.





Using the Robots.txt File
We will reveal how creating this file allows you to influence the indexing of your website by controlling which parts should be visible to search engines and which should not. You will also learn how robots.txt can be used to reduce server load and optimize resource usage by telling search engines which parts of the site to ignore. Using robots.txt samples, we’ll look at how using a robots.txt file can be an important tool for preventing excessive traffic and conserving your server’s bandwidth. First, let’s figure out what robots.txt is.
What is robots.txt?
Robots.txt is a text file that is injected into the root directory of a domain that instructs search engine robots to crawl the pages of your website. In practice, robots files tell web spiders whether they can crawl certain folders on a website. These scanning instructions are defined by “denying” or “allowing” access to all or none or specific scanners.
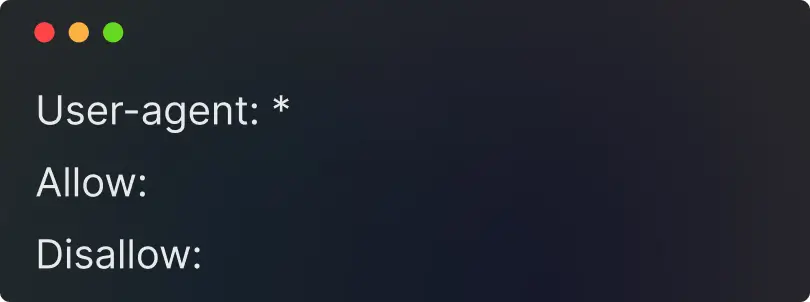
Creating the robots.txt file
Creating a robots.txt file is easy, you just need to know a few specific commands.
- You can create this file using a notepad on your computer or any other text editor you like.
- You also need to have access to the root folder of your domain, as that is where you should save the generated file.
- To create a robots.txt file, you need to go to the root folder of your domain and save the file there.
Key requirements for the robots.txt file
- There should be one robots.txt file per website.
- In order for robots.txt to be found, always add it to your home directory or root domain.
- Each subdomain of the root domain uses different robots.txt files. This means that both blog.example.com and example.com must have their own robots.txt files (blog.example.com/robots.txt and example.com/robots.txt).
- The robots.txt file is case-sensitive: the file must be named “robots.txt” (not Robots.txt, robots.TXT, or anything else).
- The file will consist of various directives grouped by the job to which they apply. Additionally, each policy group cannot contain empty rows. Also consider that each group of directives begins with the user-agent field, which, by the way, serves to identify the robot to which the specified directives belong.
- Some users (robots) may ignore the robots.txt file. This is especially true of less ethical trackers such as malicious bots or email scrubbers.
- The robots.txt file is public: just append /robots.txt to the end of any root domain to view the policies for that website. This means that anyone can see which pages you want or don’t want to track, so don’t use them to hide a user’s personal information.
- It is generally recommended that you specify the location of any sitemap associated with this domain at the bottom of your robots.txt file.
Syntax and directives of robots.txt
The syntax is very simple:
- You assign rules to bots by specifying their user agent (search engine bot) followed by directives (rules).
- You can also use the star symbol to assign directives to any user agent. This means that this rule applies to all bots, not a specific one.
Symbols of the robots.txt file
There are five common terms you’re likely to encounter in a robots file:
User-agents. Specifies the name of the specific web scanner to which you are providing scanning instructions.
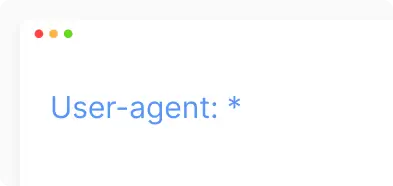
- Applies to all search bots.
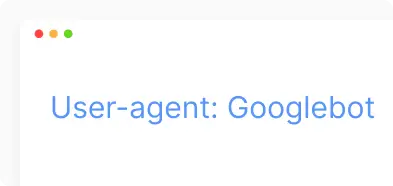
- Applies specifically to Googlebot or other defined bots.
Disallow robots.txt. The command used to tell the user agent not to crawl the given URL. Only one “Disallow:” line is allowed per URL.
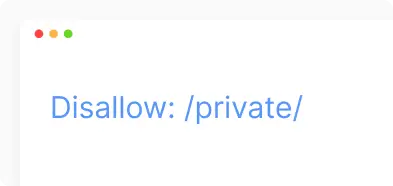
- Deny access to a specific folder or page.
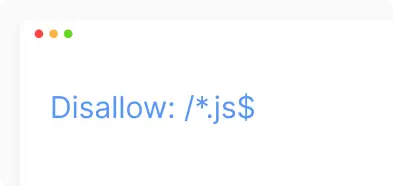
- Tells search bots that all files with the extension “.js” in the site paths should not be indexed.
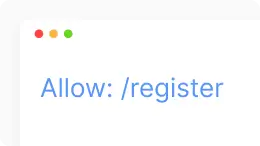
Allow robots.txt. Applies to Googlebot only. This command tells Googlebot that it can access the page or subfolder even if its subfolder is disabled.
Crawl-delay robots.txt. The number of seconds the scanner should wait before loading and scanning the page’s content. Note that Googlebot does not recognize this command, but the crawl speed can be adjusted in Google Search Console.

- This means that robots should wait 30 seconds between each access.
Robots.txt Sitemap. Використовується для виклику розташування будь-якої XML карти сайту, пов’язаної з цією URL-адресою. Зверніть увагу, що ця команда підтримується лише Google, Ask, Bing і Yahoo.

Increase visibility
for your business: SEO solution for growth!
What should be closed in robots.txt
The robots file is used to give directives to search engines about areas of the website that should be excluded from crawling or indexing. Here are some examples of what might be prohibited in a robots.txt file:
- Confidential or private directories: This directive prevents search engines from accessing a website’s “private” directory, which may contain sensitive or confidential information.
- Configuration files or sensitive data: If there are such files, it is a good idea to prevent search engines from accessing them.
- Dynamic resources: If there are temporary resources or dynamically created pages that are not key for indexing, you can exclude them from search engines.
- Test or development versions: If a website has versions that are only used for testing or development, it is a good idea to exclude them from search engines.
- Sections that generate useless traffic: If there are parts of the site that generate useless traffic or are not relevant to search engines, these can also be closed.
Examples of using the robots.txt file
Robots.txt example 1. Search engines can crawl your entire site
There are several ways to tell search engines that they can crawl your entire site. You can use this syntax:

Alternatively, you can leave the robots.txt file empty (or not have it at all).
Robots.txt example 2. Prevent Google from crawling your site
In this example, only Google will not be able to crawl the site, while all other search engines will be able to:

Note that if you disallow Googlebot, the same disallowance will apply to all Google bots. For example, also for the Google News or Google Images scanner.
Robots.txt example 3. Prohibit scanning of a specific file
In this example, no search engine can crawl the PDF file “about-robotstxt.pdf” located in the “pdf” folder:

How to check the robots.txt file
Checking the robots.txt file can be an important step in optimizing the indexing of your website by search engines. There are several ways to do this:
- Open your browser and enter the URL of your website, adding /robots.txt to the end (eg http://example.com/robots.txt).
- You will see the text content of your robots.txt file. Check that the rules are displayed as you expect.
- In your own Google Webmaster Account, you can check the “Coverage” section and select “robots.txt”.
- Here you will see the status of your robots.txt file and any issues that may be affecting indexing.
- In Chrome or Firefox, you can use the built-in developer tools. In the “Network” tab you will find the option to view the robots.txt file.
- Just type chrome://net-internals/#hsts (for Chrome) or about:config (for Firefox) in the address bar and enter robots.txt in the “Location” section
- There are online tools such as “Google robots.txt Tester” that allow you to check your robots.txt file for errors and correct rules.
Make sure that your robots file contains the correct directives and is free of errors to effectively manage the indexing of your website.
Conclusions
Robots.txt is a simple but very powerful file. To use it consciously means to improve optimization and positioning in search engines. However, its use without knowledge can cause serious damage to the organic visibility of the site. Understanding its key directives and syntax is crucial to avoid unintentional blocking of important content, leading to ‘blocked by robots.txt’ issues in search engine results.
You may also like it

Brand identity: The key to brand recognition and SEO success
Every product has its own unique feature that sets it apart from other brands. It could be a special font, a unique mascot, or an interesting logo with the right...
What is a dynamic URL and its impact on SEO
A dynamic URL (Uniform Resource Locator) is a web address that changes depending on the user's request or specific parameters. It differs from a static
Press releases as an important part of your SEO strategy: Brand Push Services
SEO is the best promotion on the Internet that helps attract more potential clients and improve your market position. The use of press releases is an important SEO...